Research Article - Biomedical Research (2017) Volume 28, Issue 10
Ear biometrics for human classification based on region features mining
Mohd Shafry Mohd Rahim1*, Amjad Rehman1, Fajri Kurniawan1 and Tanzila Saba2
1MaGIC-X UTM-IRDA Digital Media Centre, Universiti Teknologi Malaysia, Skudai, Johor, Malaysia
2College of Computer and Information Sciences, Prince Sultan University, Riyadh, Saudi Arabia
- *Corresponding Author:
- Mohd Shafry Mohd Rahim
MaGIC-X UTM-IRDA Digital Media Centre
Universiti Teknologi Malaysia, Malaysia
Accepted date: March 7, 2017
Abstract
This paper presents an ear biometric approach to classify humans. Accordingly an improved local features extraction technique based on ear region features is proposed. Accordingly, ear image is segmented in to certain regions to extract eigenvector from all regions. The extracted features are normalized and fed to a trained neural network. To benchmark results, benchmark database from University of Science and Technology Beijing (USTB) is employed that have mutually exclusive sets for training and testing. Promising results are achieved that are comparable in the state of art. However, a few region features exhibited low accuracy that will be addressed in the subsequent research.
Keywords
Feature extraction, Region-based features, Eigenvector, Ear biometrics
Introduction
Biometrics corresponds to self-verification or identification by considering personality such as behavioral or physical, which are related to the individual features. Therefore, the person could be identified based on self-personality, rather than by external identity such as ID card or password [1,2].
Nowadays, numerous automated biometrics systems have been used for facial recognition, fingerprint recognition, hand identification, ear identification. Gait analysis would significantly improve the effectiveness of forensic work adopted by security forces. Literature confirms that ear could be used for human identification [3]. Iannarelli [4] has proven the ear is a stable anatomical as it doesn’t vary significantly throughout human life. Moreover, the ear is visible and uncovered to allow a good hearing. During biometrics enrolment, people are more comfortable taking ear image rather fingerprint and face images [5]. The ear does not have emotional traits like face expressions. Burge and Burger [6] construct neighborhood graph by transforming the detected edges into Voronoi diagrams. Hurley et al. [7] develop an approach by extracting the energy features in-ear image. Ansari et al. [8] originate a method to locate the outer ear based on carrying out convex curved of edge regions. Although yielding accurate registrations, their method yields some false positives matching. It is due to the occlusion mistakenly included in-ear convex. Furthermore, the elliptical shape of the outer ear is considered by Arbab et al. [9]. They achieve promising results while dealing with occlusion. However, registration accuracy is same as compare to manual registration. Viola et al. [10] propose a robust approach to detect the object using Haar-like features. Nevertheless, the method produces inaccurate localization. Abate et al. [11] enhance method by taking the centroid of ear edge for localization. Unfortunately, it is excessively sensitive to occlusion. In addition, Abdel et al. [12] utilize Hausdorff edge template matching with skin colored regions of an image. However, it requires good lighting conditions to detect the skin region accurately and hair around ear could disturb edge detection of the outer ear [13-16]. Even numerous studies have been reported in the literature, however, unconstrained ear recognition still need to be improved [17,18]. This study proposes a new method to recognize ear image at a different pose. In this article author focus on presenting the region-based feature extraction methods developed for ear biometrics applications. Section 2 presents region-based methods of ear feature extraction, section 3 exhibits results and analysis and the conclusion is drawn in section 4.
Proposed Method
Overview of proposed method
This section presents a robust region-based approach to extract features of ear image extracted from a human head. Moreover, unconstrained ear images are captured at various angles including natural occlusions (hair and earring) and different illumination. However, ear image captured from the backside is avoided. The USTB ear images size is standard (300 × 400 pixels). Some samples from USTB ear database [19] are presented in Figure 1.

Figure 1: Ear image samples from USTB database [19].
Images at high illumination are too bright, so edges of the ear are unclear. Hence, the image contrast is normalized to obtain ear image with clear edge [20-23]. Therefore, pre-processing is performed to enhance images quality. Literature cited in the previous section is only suitable for side pose of the ear. Thus, this paper proposed local features to adapt pose variation of the ear. Accordingly, the ear image is sliced into several regions to extract local and independent features mainly due to the following reasons [24,25].
1. Decomposing the image into some region gives better textural information and therefore, contributes accurate recognition system.
2. Partitioning the ear texture can eliminate unclear regions into several blocks that reduce noisy regions to a minimum.
3. Local and global information of every region provides both important texture features and a high level of robustness.
Two geometrical features defined as Triangle Ratio Method (TRM) and Shape Ratio Method (SRM) is considered as proven yield promising accuracy. Furthermore, eigenvector feature is applied on each region. The proposed method works in the small region to handle pose variance. The different pose makes some part of the ear unclear or not fully captured. In such case, only some region of the ear will have significant features [26-30]. Finally, the extracted features are used as training data for the neural classifier. However, samples not included as training data, considered as testing data and output of the ANN is whether ear image can be identified or not [31-33].
Pre-processing
The ear images have different contrast so the local contrast is applied rather global. Hence, Contrast Limited Adaptive Histogram Equalization (CLAHE) that can adapt the local contrast rather global contrast [34,35]. This method limits the slope of gray level to avoid saturation. It is using the clip limit factor to avoid over-saturation of the images, particularly in identical areas that present high peaks in the histogram [36].
Slicing image into region
The following steps are implemented to cut ear image into several regions.
1. The input image is denoted by m × n matrix.
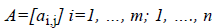
Where, m and n are width and height of image respectively. The size of region matrix (mslice and nslice) is calculated as below:
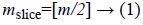
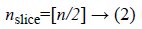
2. Then, 6 region matrices are derived from matrix A according to size reference, mslice and nslice.
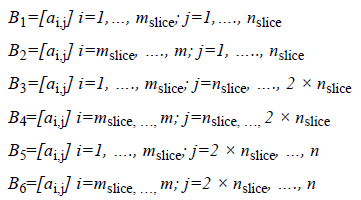
3. Finally, the size of each region matrix is expanded with respect to k (k<m, n) that produce overlapped matrix.
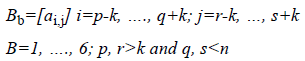
The result of slicing procedure is depicted in Figure 2. It produces six ear image region before expanded (Figure 2a) and after expanded with k=10 (Figure 2b). Expanded regions have overlapped portion that taken from its neighborhood. Further, eigenvector features are extracted from those regions.

Figure 2: Six regions of the ear image.
Feature extraction
In the proposed method, local and global feature are extracted from ear images identify human. Global features based on geometrical parameters and properties from ear edges. In this regards, edge detection method is performed to produce edges from ear images, in which the extracted edges contain unique information regarding geometrical and shape properties of the certain ear. After that, the feature vector is reconstructed from extracted edges on the basis of the adopted geometrical parameters [37-39].
Local features are extracted from a part of ear image. Hence, a slicing procedure as explain in section C is performed to split the ear image into apart. Both features are described as below:
1. Two global features originated by Choras [12] are briefly described as follow:
a) Triangle ratio method: This feature can represent contour in ear image by considering the invariant geometrical features. The critical step is selecting longest contour from ear edges. Afterward, using Equation 3 the triangle ratio is computed.
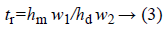
hm and hw are both represent the height of the triangle,
w1 and w2 are both correspond to sum of the length of two triangle side.
b) Shape ratio method: This feature calculated shape ratio of the main contour. The shape ratio defined as kk is described in Equation 4.
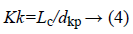
Lc is the contour length given by Equation 5, dkp is the length of the line connecting the ending points of each contour given by Equation 6.
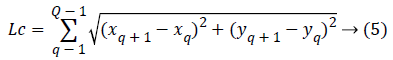
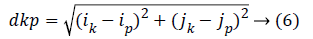
Q-number of contour points, c-number of contours, for c=1, ..., C, (x, y)-coordinates of contour points, q-indexation of the current contour point.
2. Local features: In the early 90s, an eigenvector is commonly adopted in the field of face recognition [26]. Moreover, it is successfully implemented in various systems [27-29]. Hence, this study considered eigenvector as a feature for local ear image. Generally, an eigenvector is transforming a high dimension image into a lower dimension, in which will be recognized. Variance within vector space becomes clear and measurable. The Eigenvalues and eigenvectors are defined in Equation 7.
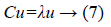
Where, the average covariance image matrix is denoted by C. λ corresponds to the Eigen values of C and u represents to the eigenvectors. The eigenvector of each slice is extracted as follow:
a) Each ear slice is grouped into six image set. Suppose, region I of ear image in training set should be in the same grouped, and similarly with another region.
b) The average vector in the region image set is calculated by summing the entire column vector and divide by the number of images. Equation 8 described the average vector.
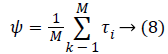
c) Using above ψ vector, the normalized mean of the image can be derived using Equation 9. τi represent the differences between the set and the image. Afterward, C can be calculated using Equation 10.
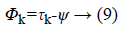
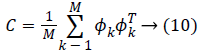
The eigenvectors that consider from highest Eigen values is representing the significant features of the image set. Hence, it can use to estimate any image in the set. In this study, each slice has an eigenvector that consists of six Eigen value.
Recognition
The training set is normalized and is fed to the neural classifier for training phase. A number of experiments are conducted with USTB ear database to obtain optimal ANN structure [40-42]. Finally, optimal structure of ANN is depicted in Table 1.
| Input | Hidden | Output | Momentum/learning rate |
|---|---|---|---|
| 64 neuron | 31 neuron | 8 neuron | 0.05 |
Table 1. Neural network optimal structure.
Result and Discussion
The proposed identification technique is tested on University of Science and Technology Beijing (USTB) ear database [11]. USTB database contains multi-pose ear data set composed of 79 subjects. The ear image is taken on a different angle by 5o in the range [0°-45°]. Additionally, images have different lighting condition. In this study, only small set images contain 750 ear images of 142 individuals with various pose or view are considered for the experiment. Furthermore, 600 ear images are used for a training session and the remaining images are considered for testing and evaluation. The experiments are conducted in two sections. In the first experiment, the ear identification is performed with global feature only. In the next section, identification is performed with a fusion of global feature and the eigenvector feature that extracted from segmented slice regions (local feature). Table 2 depicts that fused features, local and global features, achieved better recognition rate. However, additional features also increase computation cost.
| Extracted features | ANN Structure | Number of features | Accuracy |
|---|---|---|---|
| TRM-SRM | I | 64 | 86.67% |
| TRM-SRM-Eigen vector | II | 64+36 | 93.33% |
Table 2. Neural network optimal structure.
Conclusion
This paper has presented a feature extraction method based on local and global features. The local features are extracted from small region rather the whole image in order to handle invariant pose. In this regards, a simple and effective slicing procedure is presented. Following pre-processing stage, an edge detection algorithm is performed and global features are extracted based on detected edges. It includes Triangle Ratio Method (TRM) and Shapes Ratio Method (SRM). Finally, to extract local features image is sliced into six regions. The feature vector is fed to the neural classifier to identify humana ear.
References
- Rehman A, Saba T. Document skew estimation and correction: analysis of techniques, common problems and possible solutions. Appl Artificial Intel 2011; 25: 769-787.
- Saba T, Rehman A, Sulong G. Improved statistical features for cursive character recognition. Int J Innov Comp Inform Contr 2011; 7: 5211-5224.
- Husham AHA, Saba M, Rehman TA, Saleh AJ. Automated nuclei segmentation of malignant using level sets. Microscopy Research Technique 2016.
- Iannarelli A. Ear identification, forensic identification series. Paramont Publ Company 1989.
- Meethongjan K, Dzulkifli M, Rehman A, Altameem A, Saba T. An intelligent fused approach for face recognition. J Intel Sys 2013; 22: 197-212.
- Burge M, Burger W. Ear biometrics. Biometrics Personal Identification Networked Society 1998; 273-286.
- Hurley DJ, Nixon MS, Carter JN. Force field energy functional for ear biometrics. Computer Vision and Image Understanding 2005; 98: 491-512.
- Ansari S, Gupta P. Localization of ear using outer helix curve of the ear. Proc Int Conf Comp Theory Appl 2007; 688-692.
- Arbab ZB, Nixon MS. On shape-mediated enrolment in ear biometrics. Adv Vis Comp Lecture Notes Comp Sci 2007; 4842: 549-558.
- Viola P, Jones M. Robust real-time object detection. Int J Comp Vis 2004; 57: 137-154.
- Abate AF, Nappi M, Riccio D, Ricciardi S. Ear recognition by means of a rotation invariant descriptor. Proc 18th Int Conf Patt Recogn 2006; 4: 437-440.
- Abdel-Mottaleb M, Zhou J. Human ear recognition from face profile images. Adv Biometrics 2005; 3832: 786-792.
- Muhsin ZF, Rehman A, Altameem A, Saba A, Uddin M. Improved quadtree image segmentation approach to region information. Imag Sci J 2014; 62: 56-62.
- Neamah K, Mohamad D, Saba T, Rehman A. Discriminative features mining for offline handwritten signature verification. 3D Res 2014; 5.
- Mundher M, Muhamad D, Rehman A, Saba T, Kausar F. Digital watermarking for images security using discrete slantlet transform, Appl Math Inform Sci 2014; 8: 2823-2830.
- Norouzi A, Rahim MSM, Altameem A, Saba T, Rada AE, Rehman A, Uddin M. Medical image segmentation methods, algorithms, and applications. IETE Technical Rev 2014; 31: 199-213.
- Rehman A, Mohammad D, Sulong G, Saba T. Simple and effective techniques for core-region detection and slant correction in offline script recognition. Proc IEEE Int Conf Sig Imag Proc Appl 2009; 15-20.
- Saba T, Rehman A, Sulong G. Cursive script segmentation with neural confidence. Int J Innov Comp Inform Contr 2011; 7: 1-10.
- http://www.ustb.edu.cn/resb/
- Choras M. Further developments in geometrical algorithms for ear biometrics. FJ Perales Fisher AMDO 2006; 4069: 58-67.
- Joudaki S, Mohamad D, Saba T, Rehman A, Al-Rodhaan M, Al-Dhelaan A. Vision-based sign language classification: a directional Review. IETE Technical Rev 2014; 31: 383-391.
- Saba T, Rehman A, Altameem A, Uddin M. Annotated comparisons of proposed preprocessing techniques for script recognition. Neur Comp Appl 2014; 25: 1337-1347.
- Lung JWJ, Salam MSH, Rehman A, Rahim MSM, Saba T. Fuzzy phoneme classification using multi-speaker vocal tract length normalization. IETE Technical Rev 2014; 31: 128-136.
- Saba T, Almazyad AS, Rehman A. Online versus offline Arabic script classification. Neur Comp Appl 2016; 27: 1797-1804.
- Soleimanizadeh S, Mohamad D, Saba T, Rehman A. Recognition of partially occluded objects based on the three different color spaces (RGB, YCbCr, HSV). 3D Res 2015; 6: 1-10.
- Younus ZS, Mohamad D, Saba T, Alkawaz MH, Rehman A, Al-Rodhaan M, Al-Dhelaan A. Content-based image retrieval using PSO and k-means clustering algorithm. Arab J Geosci 2015; 8: 6211-6224.
- Al-Ameen Z, Sulong G, Rehman A, Al-Dhelaan A, Saba T, Al-Rodhaan M. An innovative technique for contrast enhancement of computed tomography images using normalized gamma-corrected contrast-limited adaptive histogram equalization. EURASIP J Adv Sign Proc 2015; 32.
- SabaT, Rehman A, Al-Dhelaan A, Al-Rodhaan M. Evaluation of current documents image denoising techniques: a comparative study. Appl Artificial Intel 2014; 28: 879-887.
- Nodehi A, Sulong G, Al-Rodhaan M, Al-Dhelaan A, Rehman A, Saba T. Intelligent fuzzy approach for fast fractal image compression. EURASIP J Adv Sign Proc 2014.
- Ahmad AM, Sulong G, Rehman A, Alkawaz MH, Saba T. Data hiding based on improved exploiting modification direction method and Huffman coding. J Intel Sys 2014; 23: 451-459.
- Saba T, Rehman A, Sulong G. An intelligent approach to image denoising. J Theor Appl Inform Technol 2010; 17: 32-36.
- Saba T, Al-Zahrani S, Rehman A. Expert system for offline clinical guidelines and treatment. Life Sci J 2012; 9: 2639-2658.
- Harouni M, Rahim MSM, Al-Rodhaan M, Saba T, Rehman A, Al-Dhelaan A. Online Persian/Arabic script classification without contextual information. Imag Sci J 2014; 62: 437-448.
- Fadhil MS, Alkawaz MH, Rehman A, Saba T. Writers identification based on multiple windows features mining. 3D Res 2016; 7: 1-6.
- Waheed SR, Alkawaz MH, Rehman A, Almazyad AS, Saba T. Multifocus watermarking approach based on discrete cosine transform. Microscop Res Tech 2016; 79: 431-437.
- Al-Turkistani H, Saba T. Collective intelligence for digital marketing. J Business Technov 2015; 3: 194-203.
- Husham A, Hazim Alkawaz M, Saba T, Rehman A, Saleh Alghamdi J. Automated nuclei segmentation of malignant using level sets. Microsc Res Tech 2016; 79: 993-997.
- Saba T, Rehman A, Sulong G. An intelligent approach to image denoising. J Theor Appl Inform Technol 2010; 17: 32-36.
- Rad AE, Rahim MSM, Rehman AAA, SabaT. Evaluation of current dental radiographs segmentation approaches in computer-aided applications. IETE Tech Rev 2013; 30: 210-222.
- Rad AE, Rahim MSM, Rehman A, Saba T. Digital dental X-ray database for caries screening. 3D Res 2016; 7: 1-5.
- Jamal A, Hazim Alkawaz M, Rehman A, Saba T. Retinal imaging analysis based on vessel detection. Microsc Res Tech. 2017; 1-13.
- Patwa N, Kavuri SP, Grandhi B, Hongrak K. Study on effectiveness of location-based advertising on food service industry in Sydney. J Bus Technov 2016; 4: 112-124.