Research Article - Biomedical Research (2018) Volume 29, Issue 13
Artificial bee colony (ABC) algorithm and fuzzy based discriminative binary descriptor for partial duplicate medical image search in health care applications
Roselin Mary Clare K1* and Hemalatha M2
1Research Scholar, Research and Development Centre, Bharathiar University, Coimbatore, India
2Dr. SNS Rajalakshmi College of Arts and Science, Coimbatore, India
- *Corresponding Author:
- Roselin Mary Clare K
Research Scholar
Research and Development Centre
Bharathiar University, India
Accepted on November 24, 2017
DOI: 10.4066/biomedicalresearch.29-17-3426
Visit for more related articles at Biomedical ResearchAbstract
Objective: To determine the duplicate search of medical images in health care industry to improve treatment and diagnosis of Brain Tumor (BR).
Methods: Medical image duplication search was treated in the present work. Fuzzy Sigmoid Kernel (FSK)-Subspace Clustering (SC)-Edge Scale-Invariant Feature Transform algorithm (FSK-SC-ESIFT) algorithm is presented for partial duplicate search of medical images. It contains five major steps such as deblurring, discovery of steady corner points, map extraction, detection of most discriminative bin and subspace clustering. In this research method, the image deblurring is accomplished by utilizing Artificial Bee Colony (ABC) algorithm. The constant corner point discovery is carried out by Harris Corner (HC) and map extraction is accomplished by Principal Component Analysis (PCA). Then FSK Function is used to discover the most discriminative bin selection. SC is presented for quick image retrieval.
Results: The MRI brain tumor images are used for evaluation. The results are measured using Mean Average Precision (MAP) with respect to r, D and w parameters. FSK-SC-ESIFT produces higher MAP of 70% for r value of 3.5.
Conclusion: Finally, the results show that the proposed work gives greater performance compared to the previous work.
Keywords
Partial duplicate mobile search, Edge scale-invariant feature transform, Cornet point detection, image deblurring, Artificial bee colony, Principal component analysis, Subspace clustering algorithm, Fuzzy sigmoid kernel.
Introduction
In recent times there becomes known a class of image search applications whose query images taken from a mobile device similar to a camera mobile phone. For specified a query image, the technique is to place its next to- and partial-duplicate images in a huge amount of web images and medical images. There are a lot of applications for such a system, such as identifying copyright violations or placing super quality or canonical, versions of a less-resolution or changed image. In image-based object retrieval, image deviations could be because of 3D view-point change, lighting, object deformations, or even object-class variability [1].
Local image patch descriptors have turn out to be a broadly utilized tool in computer vision, utilized for image retrieval, object/scene identification, face alignment face verification, and image stitching. Their helpfulness and significance are confirmed by the huge amount of publications which presented diverse descriptors. In recent times binary key point descriptors [2,3] gained substantial interest since they need fewer storage and give sooner matching times matched up to descriptors which encode the patch appearance since a vector of real numbers.
A codebook-free algorithm is utilized for extensive mobile image search. In this technique, it uses a new scalable tumbled hashing method to make sure the recall rate of local feature matching. After that, it improves the matching precision by proficient confirmation with the binary signatures of these local features [4]. As a result, this technique attains rapid and exact feature matching without an enormous visual codebook. Furthermore, the quantization and binarizing functions in the method are free of little groups of training images and simplify well for varied image datasets.
Content-Based Image Retrieval (CBIR) has been a main issue in multimedia for years. There are numerous techniques utilized invariant local features to signify images that use the bag-of-visual-words model [5] and the typical inverted index structure for scalable image search.
Usually, such an image search structure comprises four essential key modules, with feature extraction, feature quantization, image indexing, and image ranking. For feature extraction, the very well-liked and effectual local descriptor is the SIFT [6], that is extorted on main points or regions identified by Difference of Gaussian (DoG) and Hessian affine detector. Afterwards, there have been more attempts on intending local descriptors with a superior effectiveness and equivalent discriminability e.g., edge-SIFT [7].
At feature quantization, every local descriptor is plotted or hashed to one or various visual words and after that an image is denoted by a collection of visual words. Subsequently, inverted index structures are willingly taken up to index significant image databases for image search.
At the online retrieval phase, the shared visual words among a query image and database images could be effortlessly recognized by searching the inverted index lists. The likeness amid the query and database images is deliberated by a weighted formulation dependent upon those shared visual words.
At last, those appropriate database images are ordered by their likeness scores and offered to users. The primary retrieval outcomes possibly will be re-ranked by certain post-processing methods, for instance the query expansion, feature augmentation, or geometric verification.
Zhou et al. [8] utilized to alter SIFT descriptors to 256 bit binary vectors by a scalar quantization method. Devoid of guiding a codebook, this technique chooses 32 bits from the 256 bit vector as a codeword for indexing and search. The disadvantage of this method is that the respite 224 bit per feature ought to be stored in the inverted index that casts a weighty memory load. A new query-sensitive ranking algorithm to order PCA-based binary hash codes to look for neighbors for image retrieval that successfully progresses the precision of feature matching however at the risk of missing certain exact matches.
Literature Review
Liu et al. [9] introduced the problem of the loss of aspects discriminative power because of quantization and the low usage of spatial relationships amongst visual words. This work proposes new methodology coupling visual and spatial information constantly to advance discriminative power; features of the query image are primarily clustered by both equivalent visual features and their spatial relationships. Afterwards clustered features are gently matched to ease quantization loss. Experimentations on both UK Bench database and a gathered database with over one million images prove that the technique attains 10% enhancement over the technique with a vocabulary tree and bundled feature methodology.
Grauman et al. [10] research kernel based classification methodology that plots unordered feature sets to multiresolution histograms and calculates a weighted histogram intersection in this space. This “pyramid match” calculation is linear in the amount of features, and it completely discovers associations dependent upon the optimum resolution histogram cell where a matched pair foremost comes out. Because the kernel does not castigate the existence of additional features, it is vigorous to litter.
This technique proves the kernel function is positive-definite, making it legal for utilize in learning algorithms whose best possible solutions are assured only for Mercer kernels. Nevertheless it contains problem with system complexity.
Jegou et al. [11] offers two contributions to progress accurateness and speediness of an image search system dependent upon bag-of-features: a Contextual Dissimilarity Measure (CDM) and a competent search structure for visual word vectors.
This measure (CDM) considers the local distribution of the vectors and iteratively guesstimates distance correcting terms. These terms are consequently utilized to bring up to date a previous distance, thus changing the neighbourhood structure. Experimentation outcomes on the particular dataset prove that the technique considerably does better than the state-of-the-art in regards to accurateness.
Housing et al. [12] concentrates on biased duplicate web image retrieval, and bring in a new method, spatial coding, to encode the spatial relationships amongst local features in an image. This spatial coding is both competent and effectual to find out false matches of local features amid images, and could significantly get better retrieval performance.
Experimentations in partial-duplicate web image search, utilizing a database of one million images, expose that the technique attains a 53% enhancement in mean average precision and 46% decrease in time cost over the baseline bagof- words technique.
Xu et al. [13] presented a New Artificial Bee Colony (NABC) algorithm that alters the search pattern of both working and observer bees. A solution pool is built by storing up certain most excellent solutions of the present swarm. Novel candidate solutions are produced by looking for the neighbourhood of resolutions arbitrarily selected from the solution pool. Experimentations are carried out on a group of twelve benchmark functions. Simulation outcomes prove that this method is extensively superior or no less than similar to the original ABC and seven other stochastic algorithms.
Mair et al. [14] introduced a well-organized corner detection algorithm. Corners are favoured cues because of their two dimensional restraint and quick algorithms to identify them.
Newly, a new corner detection approach, fast, has been presented which outperforms previous algorithms in both computational performance and repeatability. On the other hand it contains issue with attaining quality of images for extremely major dataset. PCA is winning method which has been utilized in image processing. PCA is a statistical technique underneath the broad title of factor analysis. The point of PCA is to decrease the huge dimensionality of the data space (observed variables) to the minor intrinsic dimensionality of feature space (independent variables) that are required to explain the data inexpensively. This is the case while there is a sturdy correlation amid noticed variables [15]. The major objective of this work is to introduce a new binary edge descriptor for retrieval of the medical images with increased retrieval accuracy and the retrieval time. In this work, FSK is utilized to choose the highly informative bins and the relevance kernel value amid images is labelled. PCA algorithm is utilized for well-organized map extraction and advances the functioning of Edge-SIFT. Visual vocabulary tree could be produced via subspace clustering with the described similarity measurement is utilized for proficient visual word production. Edge-SIFT are binary, compacted and permits for speedy similarity calculation utilizing the research methodology.
Experimental Methodology
The structure defines that the research ABC algorithm and Hybrid Harris Corner and Edge-SIFT extraction together with PCA in Figure 1.

Figure 1: Overall architecture diagram.
ABC for image deblurring
The ABC contains the benefit of applying less control parameters when matched up with other swarm optimization algorithms. Both approximate image and blur function are discovered via this depiction. In ABC, a colony of artificial forager bees (agents) looks for well-off artificial food resources (fine way out for a specified issue). In order to employ ABC, believed optimization issue is initially transformed to the issue of identifying the finest parameter vector that reduces an objective function. After that, the artificial bees arbitrarily find out a population of preliminary solution vectors and afterwards iteratively get better them by applying the methods: Approaching improved solutions via a neighbours search method whilst discarding poor solutions. The colony of artificial bees consists of three sets of bees: applied bees linked with accurate food resources, onlooker bees inspecting the dance of used bees within the hive to select a food resource, and scout bees looking for food resources arbitrarily.
Both onlookers and scouts are as well-known as jobless bees. At first, all food source positions are found by scout bees. Afterwards, the nectar of food resources are utilized by applied bees and onlooker bees, and this repeated exploitation will eventually root them to turn out to be bushed. After that, the applied bee that is exploiting the exhausted food resource turn out to be a scout bee looking for additional food resources another time. In other phrases, the applied bee whose food resource has been shattered turns out to be a scout bee. In ABC, the place of a food resource denotes a probable resolution to the issue and the nectar amount of a food resource in relation to the quality (fitness) of the related resolution. The amount of employed bees is equivalent to the amount of food resources (solutions) a severe applied bee is related with unique one food resource. The common method of the ABC algorithm is in this manner initialization phase.
Every vectors of the population of food resources xij, are initialized (m=1,..., SN), SN: population size) by scout bees and control parameters are set
Xij=lj+rand (0, 1) × (uj-lj) → (1)
Here lj and uj are e the lower and higher bound of the parameter correspondingly. rand is the random generator function of values with zero mean and unity variance.
Repeat
Employed bees phase
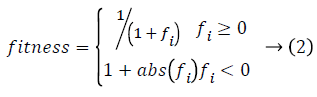
Here fi is the best fitness function value
Onlooker bees phase
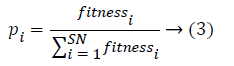
Scout bees phase
Remember the best solution attained until now
UNTIL (Cycle=Maximum Cycle Number (MCN))
When using ABC algorithm first need to compute the fitness function fi. In this work, the fitness function is obtained by using Equation 4. It produced local bees best and global bee best values based on the highest intensity and lower error values. Thus it is used to provide deblurred image with high quality. It is used to reduce the Peak Signal to Noise Rates (PSNR) in the given blurred images more optimally. PSNR value is calculated by measuring the quality of restored image alongside original image.
fi=PSNR
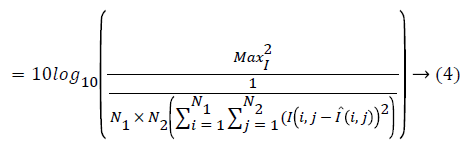
Where: N1 and N2=The size of the image ‘I’=The original image for evaluating the quality of the various filters I ̂=The image obtained after applying the respective filter ‘Max’=The maximum possible intensity of the image. It is utilized to amplify the PSNR in the specified blurred images best possibly. The corner points are identified and the intensity pixel values of images are improved by utilizing ABC algorithm together with superior PSNR rate. PSNR value is computed by measuring the quality of restored image alongside real image.
Hybrid Harris corner detection (HHCD) algorithm
Corner is the point which testing function energy is very intense in any direction changes, it is one of the most important feature of the data information. The accuracy and quality of the corner detection directly affect the results of image processing, and can determine the outline features and important information of the image [16]. Corner detection are used for camera calibration, optical flow velocity measuring, motion estimation, measurement and positioning etc., and has become an important tool for image processing. Corner detection can not only keep the useful image information but also can reduce data redundancy and improve the detection efficiency [17]. To increase the corner detection accuracy as well as efficiency, the hybrid Harris corner detection algorithm is introduced in this research. A hybrid HHCD is improved by combining the Harris and improved Susan operators. Firstly, this method extracts the Harris and Susan corner feature points by using Harris and Susan operators. Secondly, this technique combines the points and performs the weight computation on the basis of two weight coefficients w1 and w2.
Harris operator
Gradient of pixels can be computed by convolution of gradient operator and image:
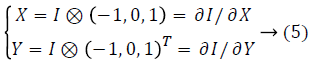
Gradient of pixels can be computed by convolution of gradient operator and image.
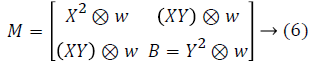
Where is ⊗ convolution operator, w is coefficient weight.
w=exp(-(x2+y2))/2δ2 → (7)
Corner response function R is defined by following:
R (x, y)=det(M (x,y))-k (trace (M (x, y)))2 → (8)
It is to be noted that k=0.04~0.06 is actually an empirical value, Det (M) refers to the determinant of matrix M, and Trace (M) stands for the trace of M.
Harris operator defines a suitable threshold T and potential corners can be obtained by comparing the angel response function R to threshold T. If R is more than T, the point can be kept as a potential corner.
Harris corners can be got by means of non-maximum suppression technique that maintains the points with maximum R in 7 × 7 window.
Improved Susan operator
Susan operator is basically an intensity-based technique. This operator receives noteworthy corners by “USAN” area. The area can be calculated as below:
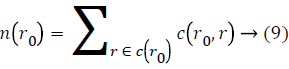
Where c (r0) refers to USAN area which center is in r0 and the c (r0, r)
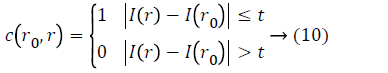
I (r) is gray value of the pixel r in the mask and I (r0) is gray value of the mask’s center r0. t is the threshold of gray value and always is 25 in this work. Finally, if the pixel’s corner response function R (r0) can be defined as follows:
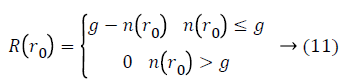
Where g indicates the geometric threshold and has an effect the sharpness of corner points are having been identified. With the aim of improving the anti-noise capability, the upper limit and lower limit of g are fixed. The range of lower limit is at all times 2~10. Susan corner points can be received by nonmaximum suppression technique that maintains the points with maximum R in 7 × 7 windows.
Corner matching
Normalized Correlation (NC) algorithm can determine if the two corners have a match by means of similarity of corners’ and gray value w1 and w2 refers the windows having same size. The center of w1 stands for the corner points set p in reference image, and the center of w2 indicates the corner points set r. μ1 indicates the mean of all the pixels’ gray value in the window w1 and μ2 indicates the mean of all the pixels’ gray value present in the window w . i stands for the size of windows. The normalized correlation coefficient has been computed as below
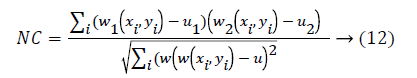
Hybrid corner detection algorithm
The Harris operator has strong stability, but its precision is lower. Susan corners’ precision is higher but its’ stability is poor. Thus, here combines the two corner detection operators together to better detect corners. The main idea is that: firstly, extract Harris corners and Susan corners from reference image and image needing registration by Harris and Susan operators respectively. After that, merge the two corner point sets to obtain the overall point sets; then select new corner point sets by a series of operations and obtain the matching corner pairs.
1. Obtain the corner point sets a=(a1, a2.... aN1) in reference image and b=(b1, b2... bM1) in image needing registration by Harris operator; use Equation 8 to compute the corner response function of all the pixels in reference image and image registration which make up of response function RH1 and RH2.
2. Get the corner point sets c=(c1, cb,..., cN2) in reference image and d=(d1, d2...dM2) in image needing registration by Susan operator and use Equation 11 to compute the corner response function of all the pixels in reference and image needing registration which make up of angel response function RS1 and RS2.
3. Corner point sets A=(A1, A2.... AN} in reference image can be received by A=a c. Corner point sets B=(B1, B2...., BM} can be got by B=b d. After this, the matrix is generated for Harris corner points and enhanced Susan corner points. Matrix RSA is defined by of the angel response function of Susan corner point sets A (A (A1, A2,.., AN)) present in reference image. Matrix RHA is defined of the angel response function of Harris corner point sets A (A (A1, A2,.., AN)) present in reference image. Matrix RHB is defined by the angel response function of Harris corner point sets B (B (B1, B2,.., BM)) in image needing registration. Matrix RSB is defined by the angel response function of Susan corner point sets B (B (B1, B2,.., BM)) present in image needing registration.
4. Perform the normalized response function RHA and RHB, RSA and RSB thereby obtaining RHA ' and RHB', RSA ' and RSB
5. Corner strength is defined as follows
R=w1 × R1+w2 × R2 → (13)
RA=w1 × RHA '+w2 × RSA ' → (14)
RB=w1 × RHB '+w2 × RSB ' → (15)
Matrix RA consists of corner strength of the corner point sets A={A1, A2,.., AN}, and matrix RB consists of corner strength of the corner point sets B={B1, B2,.., BM}.
Get the corner points in RA and RB by descending order; then maintain the first M points in case N is more than M, thereby getting {C=C1,.., CM} and {D=D1,.., DM}.
Get the corner Dj in the image needing registration that has maximum normalized correlation coefficient with Ci in the reference image, and then get Ck in the reference image that has maximum normalized correlation coefficient with Di in the image needing registration. When Ci=Ck, carry out the match Dj. Corner points in E (E=E1, E2,.., EL}) match the ones in F (F={F1, F2,.., FL}) in order.
PCA algorithm for edge map extraction.
The idea of PCA is to decrease the huge dimensionality of the data space to the minor intrinsic dimensionality of feature space that is required to explain the data inexpensively. This is the case when there is a sturdy association amid observed variables. The PCA could do prediction, redundancy elimination and feature extraction for the specified images. The symbol X to denote this complete set of edge maps. To know the procedure after the PCA the subsequent arithmetical terms are necessary. The values of the variables that is comprehensively representative of the distribution as a complete is known as average that is situated in or close to the centre to the distribution. Consider X1, X2,.... Xn represent the complete set of the edge maps for image sample of size n. The mean of the edge map is a random variable described by
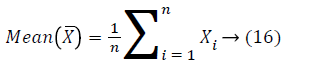
On behalf of frequencies of the above variable are F1, F2,.... Fn correspondingly the mean
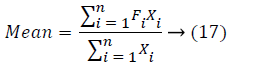
PCA is utilized to take out the exclusive characteristic of the query edge maps that differentiates it from the other edge-maps PCA believes the totality variance of the data set. For this reason specified an image input, PCA would sum up the totality variance in image values. It intends to fit this total variance into a condensed number of variables therefore dropping the edge maps. It brings about a principal component that sum up or correspond to the whole edge maps with the appropriate information taken. This is significant as the image information is big in size. A condensed data set makes calculations simple. PCA has the benefit of being an easy algorithm, dependent upon straight user defined inputs. It could recognize both subjective and constantly brings about an exclusive solution. It could be used to a semantic environment making its use advantageous.
Similarity measurement
The point of reference of every sub-edge pixel requires to be calculated online, making it costly to calculate. One likely solution to hurry up devoid of losing orientation restraint is to quantize the edge pixels in sub-vectors denoting diverse orientations.
Get better sturdiness to registration error is to lose the location restraint in similarity measurement; specifically edges from nearby locations can be also matched. The equivalent similarity measurement could be renewed as:
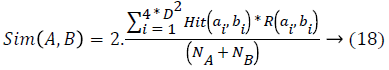
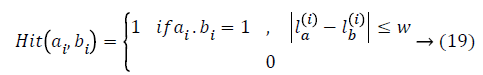
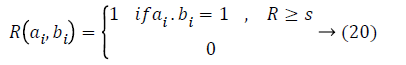
where A and B are two binary descriptors, ai, bi are the values of the ith bit in these two descriptors. N is the no. of edge pixels i.e., the nonzero bits, in a descriptor. θ is the orientation of the edge pixel, and ε is a threshold. Intuitively, edge pixels in the same location with orientation difference smaller than ε would be considered as a match. Here l represents the position of an edge pixel, and w is a threshold managing the severity of location restraint.
On the other hand, Equation 18 is as well very costly so recommend an edge expansion approach to obtain an enhanced edge descriptor. Instinctively, a binary vector could be condensed by eliminating the sparse bins that constantly illustrates Zero-value [18]. Describe the compactness of the kth bin in the initial Edge-SIFT descriptor with Equation 21, that is to say
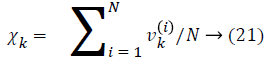
Here N represents the totality amount of gathered edge descriptors from a dataset, and vk (i) is called the value of the kth bin in the ith descriptor. The most alike bins are extorted and the likeness amid two images is computed. As a result, set a threshold for descriptor compression. Particularly, bins with firmness under the threshold will be leftover.
Fuzzy sigmoid kernel (FSK) for discriminative bins selection
According to the above mentioned strategy, to compress initial HC-ESIFT as well as to preserve its discriminative power need to choose an ideal threshold. However, such threshold is hard to decide. To conquer this issue, first select several initial bins with high compactness from initial HC-ESIFT, and then identify and add discriminative bins to get the final compressed HC-ESIFT. The matching value is determined between two images A and B is computed according to the number of matched descriptors between them. Specifically, assume that there are two images A={dA (k) Rd, k=1,2,.., NA}, B={dB (k) Rd, k=1,2,.., NB}, where dA (k), dB (k) → d-dimensional local edge descriptor, in which the values are extracted from the images. A measurement of the generic image-level is defined as,
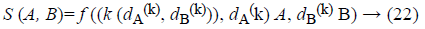 .
.
Where N → total number of local descriptors, i.e., ‘d’, in an image. where (k (dA (k), dB (k))) → local kernel matrix of a feature pair combinations of A, B respectively. f (.) → mapping function from local to Fuzzy Sigmoid Kernel (FSK) function.
The feature mapping edge pixels existing in images implying the membership functions could be personalized throughout the learning. For example, three neurons could be used to indicate “small”, “medium” and “large” fuzzy values of a variable. The Fuzzy Sigmoid Kernel (FSK) function does the modelling of the hyperbolic tangent function through linguistic variables [19]. Its description to the kernel framework is extended as below:
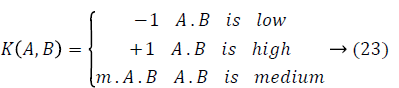
where m refers to a constant factor denoting the smoothness of the sigmoid tract. In the pretext of fuzzy logic, the sigmoid kernel can be made with a series of membership functions. In case the activation function has to be continuous, the membership limits are provided by γ ± 1/a where γ=-r/a. Therefore, Equation 23 has been re-written readily to be a function of a and r as below:
K(A,B) 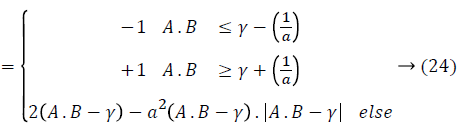
that is the final form of the newly introduced FSK function obtained from fuzzy tanh function. The important benefits of this function is that being differentiable at each point in its whole domain, it enforces quicker trainings as the final solution will be represented in a set of saturated samples Equation 23, and it allows to choose various degrees of nonlinearity by selecting the amount and complexity of the membership functions. This method is used to select n number of bins.
Subspace clustering algorithm
To generate BoWs representation, first quantize HC-ESIFT into code words. SIFT into code words. Visual vocabulary tree can be generated through clustering with the defined similarity measurement. In this research, subspace clustering algorithm is introduced for retrieval of higher similarity measure. Subspace clustering is focused to identify the subspaces of the feature space in which clusters exist. It is efficient approach to the subspace clustering visual word generation problem. Subspace clustering is the task of automatically detecting clusters in subspaces of the original feature space. Visual vocabulary tree is generated via clustering with the defined similarity measurement. To reduce the price of the in word, it decides that subspace utilizing best Subspace word from Sk in which a least amount number of objects are in the cluster.
BoWs representation is computed via quantizing local features into visual words. Consequently, quantization error is predictable and it could reduce the image retrieval competence. By dividing SC-ESIFT after discriminative bins selection (α and β), this technique could evade the quantization error. It is for example, Quantization Code (QC) and Verification Code (VC). QC is used for visual vocabulary tree generation and SCESIFT quantization, i.e., BoWs representation totalling. VC is maintained in the index file for online verification. The indexing approach is dependent upon the standard inverted file indexing framework. It is utilized to get better the more appropriate similarity outcomes and decrease the unrelated word subspaces.
If suppose the mobile image retrieval is implemented based upon client-server architecture, here the server keeps an image index and the mobile device uploads the amount of queries after that gets retrieval outcomes. With the research retrieval structure, two types of information must be sent for query from mobile devices, specifically visual word ID and VC of every SC-ESIFT. Therefore, maintaining a well-built VC would potentially advance the retrieval performance and gives low transmission cost. In addition it concentrated the amount of iterations and therefore the calculation speed is enlarged and time complexity is condensed efficiently.
The image quality is gets as superior and detection accurateness is enhanced more willingly than preceding research.
Results
Materials
There are 50 MRI brain tumor images are used for evaluation database.
The medical image database was obtained from the adults ranging from 18 to 60 y old people. The sample images are collected from this https://basicmedicalkey.com/von-hippellindau- syndrome-2/ and images are also referred from this work [20].
The results showed that the retrieval result in MRI image samples was considerably provides higher results when compared to other existing methods. An MRI brain tumor image with four samples (Figure 2) was performed to analyse the retrieval results. The HC-ESIFT edge descriptor for MRI Brain Tumor Images is shown in Figure 3.

Figure 2: MRI brain tumor images.

Figure 3: HC-ESIFT edge descriptor for MRI brain tumor images.
The partial duplicate results of MRI brain tumor samples are shown in the Figure 4.

Figure 4: MRI brain tumor images.
Parameter selection
The preliminary HC-SIFT, SC-ESIFT and presented FSK-SCESIFT edge descriptors are associated with three parameters: r that manages the size of the extorted image patch; D that chooses the size of the edge map; and w that manages the edge expansion. Experiment the consequences of these parameters in image retrieval tasks.
The consequences of r among edge detection methods such as HC-SIFT, SC-ESIFT and presented FSK-SC-ESIFT are explained in Figure 5 with respect to Mean Average Precision (MAP). From the Figure 5, it is noted that larger r is useful for performance enhancement; this is because larger image patches consists of richer edge clues that create edge descriptor more discriminative. From the Figure 5, the parameter r is set as 3.5, this concludes that the performance accuracy of FSK-SCESIFT technique is 70% which is approximately 4% and 13% higher when compared to HC-SIFT and SC-ESIFT methods respectively. It concludes that the proposed FSK-SC-ESIFT technique performs better when compared to other methods, even if the patch size increases.

Figure 5: Illustration of the effects of r.
The consequences of D among edge detection methodologies for instance HC-SIFT, SC-ESIFT and presented FSK -SCESIFT are depicted in Figure 6 with respect to MAP. It is obvious that in the Figure 6, the retrieval performance disgraces, if D is very huge or small. Instinctively, small D brings about compact descriptor; on the other hand it doesn’t loss any information of the image patches, as accurate corner points also regarded for the period of edge detection process. From the Figure 6, set the parameter D as 3.5, this concludes that the performance accuracy of FSK-SC-ESIFT technique is 67.5% for D=8 which is approximately 3% and 13.5% higher when compared to HC-SIFT and SC-ESIFT methods respectively. It concludes that the proposed FSK-SC-ESIFT technique performs better when compared to other methods, even if the size of edge map is increases.

Figure 6: Illustration of the effects of D.
The consequences of w amid edge detection methodologies for instance HC-SIFT, SC-ESIFT and research FSK-SC-ESIFT are explained in Figure 7. It could be noted that edge expansion is useful to get better the performance. On the other hand, when w=3, the adjacent edges and their corner points were accurately identified by research methodology that augment the accurateness of the system. In the meantime, the validity of edge expansion is narrowly associated to the edge map size. In the subsequent experiments, for 16 × 16 × 4 bit initial descriptor, set the value of w as 1; while for 32 × 32 × 4 bit initial descriptor, set the value of ‘w’ as 2. It gives high quality images in company with enhanced accurateness and effectiveness. From the Figure 7 set the parameter w as 3 this concludes that the performance accuracy of FSK-SC-ESIFT technique is 65.58% for w=1.5 which is approximately 10-11% and 14.56% higher when compared to HC-SIFT and SC-ESIFT methods respectively. It concludes that the proposed FSK-SCESIFT technique performs better when compared to other methods, even if the size of edge expansion is increases.

Figure 7: Illustration of the effects of w.
Validity of Edge-SIFT, HC-ESIFT, and SC-ESIFT Compression: Subsequent to choosing the parameters, therefore condense the primary Edge-SIFT and choose the discriminative bins. Analyse two kinds of primary Edge-SIFT descriptors: a 1024 bit one whose r, D, and w are 2.5, 16, and 1, and another 4096 bit one whose r, D, and w are 2.5, 32, and 2, correspondingly. Foremost condense the two descriptors to 32 bit and 64 bit by choosing condensed bins. In the Edge- SIFT descriptors compact bins are chosen by Rank boost methodology and the research work FSK-SC-ESIFT compact bins are chosen by kernel function for accurate matching.
Obviously from the Figure 8, as more bins are best possibly chosen to the compressed descriptors, their retrieval performances are enhanced extremely. This shows the validity of discriminative bins chosen approach utilizing the kernel similarity function. The condensed FSK-SC-ESIFT from the 4096 bit descriptor ultimately does better than the one from the 1024 bit descriptor. As the research work optimal bins are chosen utilizing radial basis kernel function. This proves that larger descriptor consists of richer clues; therefore more discriminative bins could be chosen. Utilizing kernel function exact identifies the matching amid two diverse images. By utilizing research PCA and FSK the most similarity features are extorted and attains superior performance. From the Figure 8 set the number of bins as 800, it concludes that the performance accuracy of FSK-SC-ESIFT (4096) technique is 79.86% for 800 bits which is approximately 19.32% and 13.53% higher when compared to HC-SIFT (4096) and SCESIFT (4096) methods respectively. It concludes that the proposed FSK-SC-ESIFT (4096) technique performs better when compared to other methods, even if the number of bins is increases.

Figure 8: Illustration of the validity of the descriptor compression.
Obviously from the Figure 9, as more bins are best possibly chosen to the compressed descriptors, their retrieval time of the proposed system is increased but decrease when compared to other existing edge description extremely. It concludes that the proposed FSK-SC-ESIFT produces average retrieval time results of 0.83125 seconds which is 0.87375 s and 0.61625 s lesser when compared to SC-ESIFT and HC-SIFT methods respectively. It concludes that the proposed work has taken only lesser retrieval time when compared to other methods.

Figure 9: Illustration of the retrieval time comparison of the various edge shift detectors.
Discussion
Accurate analysis is significant for successful treatment of Brain Tumor (BR). Image retrieval systems are able to help the radiologist in analysis of BR by retrieving related images from medical image database. Magnetic Resonance Imaging (MRI) is the generally frequently used modality for imaging BR. Through image achievement there be able to be misalignment of MR image slices appropriate to movement of patient and also the low level features extracted from MR image may not correspond with the high level semantics of BR. Because of this problem the detection of duplicate MRI image slices and the detection of specific edge, corner point’s detections becomes the most important step in medical analysis. In order to perform this tasks, in this research work new edge detectors and binary local descriptors are proposed. This proposed work is important for improving discriminative power and matching near-duplicate image patches.
It is reported that different representation of MRI images for partial duplicate search, demonstrate edge detectors and FSK based local binary descriptor where it is necessary to be considered a different patches to increase retrieval results. The retrieval results of the proposed FSK-SC-ESIFT are high when compared to other descriptors. Since the proposed FSK-SCESIFT descriptor, exact edge map and corner points are detected from the original MRI image patches. The current FSK-SC-ESIFT descriptor, not only increases the retrieval performance in addition it also enhances the quality of the input image patches by performing image deblurring. In this work first explore an ABC based image deblurring method; it is purely based on an image processing approach to increase the clarity of the MRI image samples. Because the lower level of clarity will decreases the results of partial duplicate search in BR MRI samples.
After the image patches are deblurred then edge map extraction is done by using the Principal Component Analysis (PCA) that exactly detects the edge map of the tumor parts, the original and duplicate images are matched using this edge map. This specific point majorly increases the retrieval results when compared to normal SIFT and ESIFT descriptors. By maintaining both locations and orientations of edges and compressing the sparse binary edge maps with a FSK, the final ESIFT demonstrates the well-built discriminative power with compacted representation. Additionally, fast similarity measurement is proposed and an indexing framework with flexible online verification. Therefore, the FSK-SC-ESIFT descriptor allows a precise and capable partial duplicate image search. This proposed work is ideal for computation time in partial duplicate image search. It concludes that the performance accuracy of FSK-SC-ESIFT (4096) technique is 79.86% for 800 bits which is approximately 19.32% and 13.53% higher when compared to HC-SIFT (4096) and SCESIFT (4096) methods respectively. It concludes that the proposed FSK-SC-ESIFT (4096) technique performs better when compared to other methods, even if the number of bins is increases.
Conclusion and Future Work
In this work, the algorithms are improved to raise the system accurateness and effectiveness considerably for the real images. The image normally comprises noise and therefore it leads to blurred images. To rebuild the images, the process includes for instance image denoising, feature extraction, feature quantization and image matching/retrieval. In image deblurring, the ABC algorithm is utilized to eliminate the noise by improving the fitness value of intensity. Peak Signal to Noise Ratio (PSNR) value is utilized to make sure the noise level after obtaining the deblurred image. To retrieve the partial duplicate medical images for query image, features in the medical is extracted as feature vector. The separate training phase was carried out for database feature vector extraction. In feature extraction phase, HC-ESIFT and corner points are constructed upon of local image patch. To get better the map extraction process, PCA algorithm is presented. To make SCESIFT more robust and more compact, discriminative bins selection utilizing Fuzzy Sigmoid Kernel (FSK) is research named as FSK-SC-ESIFT. In feature quantization step, visual vocabulary tree could be produced via SC with the described similarity measurement. The indexing approach is dependent upon the standard inverted file indexing structure. Therefore the FSK-SC-ESIFT is more well-organized, discriminative and robust for large-scale mobile partial-duplicate image retrieval.
As a result, utilize standard Personal Computer (PC) to imitate the mobile platform to contrast FSK-SC-ESIFT, SC-ESIFT and HC-ESIFT with Edge-SIFT in the facets of retrieval accurateness, effectiveness, and data transmission. This FSKSC- ESIFT technique is utilized to decrease the time complexity and noise rates efficiently for the given image.
Acknowledgement
The authors are grateful to SNS Rajalakshmi College of Arts and Science, for providing support and coordination to carry out this work.
Conflict of Interest
No conflict of interest associated with this work.
Contribution of Authors
The authors declare that this work was done by the authors named in this article and all liabilities pertaining to claims relating to the content of this article will be borne by them.
References
- Wu Z, Ke Q, Isard M, Sun J. Bundling features for large scale partial-duplicate web image search. IEEE Con Com Vis Pat Rec 2009; 25-32.
- Trzcinski T, Christoudias M, Fua P, Lepetit V. Boosting binary keypoint descriptors. Proc IEEE Con Com Vis Pat Rec 2013; 2874-2881.
- Yang X, Cheng KT. Local difference binary for ultrafast and distinctive feature description. IEEE Tra Pat Ana Mac Int 2014; 36: 188-194.
- Zhou W, Yang M, Li H, Wang X, Lin Y, Tian Q. Towards codebook-free: Scalable cascaded hashing for mobile image search. IEEE Tra Mul Med 2014; 16: 601-611.
- Sivic J, Zisserman A. Video Google: A text retrieval approach to object matching in videos. Null 2003; 1470-1477.
- Lowe DG. Distinctive image features from scale-invariant keypoints. Int J Com Vis 2004; 60: 91-110.
- Zhang S, Tian Q, Lu K, Huang Q, Gao W. Edge-SIFT: Discriminative binary descriptor for scalable partial-duplicate mobile search. IEEE Trans Image Pro 2013; 22: 2889-2902.
- Zhou W, Lu Y, Li H, Tian Q. Scalar quantization for large scale image search. In Proc 20th ACM Int Conf Multi Med 2012; 169-178.
- Liu X, Lou Y, Yu AW, Lang B. Search by mobile image based on visual and spatial consistency. IEEE Int Con Multi Med Exp (ICME) 2011; 1-6.
- Grauman K, Darrell T. The pyramid match kernel: Discriminative classification with sets of image features. Tenth IEEE Int Conf Comp Vis 2005; 2: 1458-1465.
- Jegou H, Harzallah H, Schmid C. A contextual dissimilarity measure for accurate and efficient image search. IEEE Con Com Vis Pat Rec 2007; 1-8.
- Housing, spatial coding for large scale partial-duplicate web image search. Proc 18th ACM Int Con Mul 2010.
- Xu Y, Ping F, Ling Yu. A simple and efficient artificial bee colony algorithm. Math Prob Eng 2013.
- Mair E, Hager G, Burschka D, Suppa M, Hirzinger G. Adaptive and generic corner detection based on the accelerated segment test. Com Vis ECCV 2010; 183-196.
- Weingessel A, Hornik K. Local PCA algorithms. IEEE Tra Neur Net 2000; 11: 1242-1250.
- Yi-bo L, Jun-Jun L. Harris corner detection algorithm based on improved Contourlet Transform. Pro Eng 2011; 15: 2239-2243.
- Cai LH, Liao YH, Guo DH. Study on image stitching methods and its key technologies. Com Tec Dev 2008; 1-4.
- Zhang S, Tian Q, Lu K, Huang Q, Gao W. Edge-SIFT: Discriminative binary descriptor for scalable partial-duplicate mobile search. IEEE Trans Image Pro 2013; 22: 2889-2902.
- Soria-Olivas E, Martín-Guerrero JD, Camps-Valls G, Serrano-Lopez AJ, Calpe-Maravilla J, Gomez-Chova L. A low-complexity fuzzy activation function for artificial neural networks. IEEE Tran Neur Net 2003; 14: 1576-1579.
- Her MY, No EJ, Kim DY, Kim SE, Lee DH. Demyelinating syndrome resembling multiple sclerosis as the first manifestation of systemic lupus erythematosus: report of two cases. J Korean Rhe Assoc 2007; 14: 78-84.